
Mixtral 8x7B, le nouveau LLM open source de Mistral AI
Les grands modèles de langage, bien qu’ils n’aient de cesse de nous surprendre, ne sont pas encore parfaits. Le manque de fiabilité et de robustesse est toujours bien présent et ralenti leur déploiement en entreprise. Pour pallier ce manque, de nouveaux modèles apparaissent tous les jours pour tenter de surpasser leurs prédécesseurs.
Parmi les sociétés qui ont à cœur de développer ces modèles, il y a Mistral AI. Cette startup française basée à Paris et née en 2023, avait déjà surpris la communauté avec le lancement de modèles entièrement open source et particulièrement performants. Leurs motivations n’ont pas manqué de nous séduire : « Nous sommes convaincus qu'en formant nos propres modèles, en les publiant ouvertement et en encourageant les contributions de la communauté, nous pouvons construire une alternative crédible à l'oligopole émergent de l'IA ». C’est poussé par ces motivations que Mistral AI vient de délivrer à la communauté un tout nouveau modèle particulièrement prometteur que nous allons discuter dans cet article.
Grands Modèles de Langage (LLM), des technologies particulièrement énergivores
Selon le paradigme actuel, l’amélioration des performances des modèles passe par l’augmentation de leur taille. Pour cause, les modèles de langage sont généralement entraînés pour disposer d’un périmètre d’action très vaste, qui se traduit par la maitrise d’un grand nombre de langues et la capacité à répondre à de nombreuses tâches (réponse à question, génération de résumés, traductions, …). Aussi, les grands modèles de langage se trouvent souvent livrés en plusieurs formats : 7B, 13B, 70B, etc. (entendre « milliard de paramètres »), les formats les plus importants affichant les meilleures performances.
Or, cette augmentation en taille rime avec augmentation de la puissance de calcul que demandent leur entraînement et leur exploitation, qui elle-même est synonyme de consommation matérielle et énergétique considérable. Alors que la question de la sobriété énergétique est sur le devant de la scène, les IA génératives se retrouvent très justement montrées du doigt.
C’est pourquoi des efforts sont donc entrepris pour se résoudre à utiliser les grands modèles de langage dans leurs déclinaisons les plus petites (7B), en contrepartie d’un sacrifice de performance.
Mixtral 8x7B, l’alternative proposée par Mistral AI
Pour tenter de répondre à cette problématique, Mistral AI vient de lancer Mixtral 8x7B !
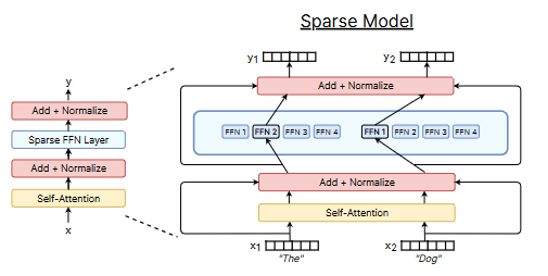
Pourquoi 8x7B ? Car il s’agit d’un modèle un peu particulier, composé de 8 modèles experts et d’un modèle de routage. A l’inférence, le modèle de routage décide lesquels des 2 sous-modèles parmi les 8 seront responsables du traitement du prompt fourni en entrée.
Ainsi, bien que le modèle comprenne au total 45 milliard de paramètres (45B), seul un échantillon (12 milliards) est utilisé pour le traitement de chaque token du prompt. Par conséquent, l’inférence s’effectue avec le même coût (en puissance de calcul) et la même latence que si le modèle n’avait que 12 milliards de paramètres, mais bénéficie du fait que chacun des sous-modèles soit spécialisé dans un domaine précis.
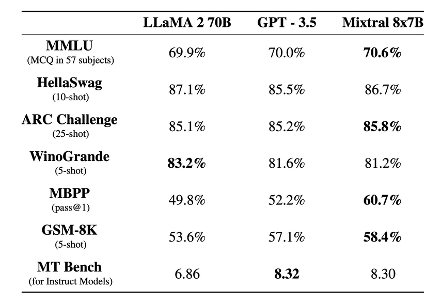
Cette stratégie appelée SMoE (pour Sparse Mixture of Experts) n’est pas nouvelle et connait un regain d’intérêt pour une utilisation appliquée au deep learning. Pour Mistral AI, ce changement de paradigme leur permet d’afficher que le modèle présente des performances équivalentes, voire supérieures, aux très connus GPT-3.5 et LLama2-70B, les modèles de langage d’OpenAI et de Meta les plus utilisés.
Par ailleurs, on notera que le modèle supporte une large fenêtre contextuelle (32k tokens) et maitrise 5 langues (Anglais, Français, Italien, Allemand et Espagnol). Une version Instruct du modèle est également disponible.
Nous suivrons de très près les avancées des grands modèles de langage qui font appel à cette technique, et il ne fait aucun doute que Mixture-8x7B sera ajouté à notre banc d’essai afin d’être intégré dans des usages métiers via la plate-forme Wikit Semantics.
Pour aller plus loin
• sur Mixtral : https://mistral.ai/news/mixtral-of-experts/
• sur Mistral AI : https://mistral.ai/news/about-mistral-ai/
• sur la technique du mélange de modèles experts : https://arxiv.org/abs/2209.01667